Investigating data structures
Concurrent data structure design is hard. This blog offers a guided tour on constructing a special-purpose concurrent map that heavily favors readers. The article will not just present yet another ready-to-use data structure. Instead, I will walk you through the design process while solving a real-world problem. I will even present dead ends that I bumped into along the way. It's a detective story for programmers interested in concurrent programming.
By the end of the article, we will have a concurrent map for storing blobs of data in native memory. The map is lock-free on a reading path and is also very conservative with memory allocations. Let's get started!
This article assumes basics in Java or a Java-like programming language.
The problem
I need a concurrent map where keys are strings and values are fixed-size blobs (public cryptographic keys). This could sound like a job for the plain old ConcurentHashMap from JDK, but there's a twist: the blobs must be available outside of the Java heap.
Why? So that callers can get a pointer to a blob and pass it to Rust code via JNI. The Rust code then uses the public key to verify digital signatures.
Here's a simplified version of the interface:
interface ConcurrentString2KeyMap {
void set(String username, long keyPtr);
long get(String username);
void remove(String username);
}
The set() method receives a username and a pointer to a key. The map outlives
the pointers it receives, so it must copy the memory under the received pointers
into its own buffer. In other words: the get() method must return a pointer to
this internal buffer, not the original pointer which was used for set().
I can assume the get() method will be used frequently and often on the hot
path, while the mutation methods will be invoked rarely and never on the hot
path.
This is roughly how readers are going to use it:
boolean verifySignature(CharSequence username, long challengePtr, int
challengeLen, long signaturePtr, int signatureLen) {
long keyPtr = map.get(username);
return AuthCrypto.verifySignature(keyPtr, PUBLIC_KEY_SIZE_BYTES, challengePtr, challengeLen, signaturePtr, signatureLen);
}
If there were no mutations, I could have just implemented a pre-populated immutable lookup directory and called it a day. However, shared mutable state brings two classes of challenges:
- Pointer lifecycle management
- Consistency of map internals
The first issue boils down to ensuring that when a map.get() returns a
pointer, the pointer must remain valid and the memory behind it must not change
for as long as needed. In our case, it means until the
AuthCrypto.verifySignature() returns.
The second issue is all about concurrent data-structure design, and we will discuss this in more detail later. Let’s explore the first issue.
Pointer lifecycle management
If our map's values were just regular objects managed by the JVM, things could
be simple: map.get() would return a reference to an object and then it could
forget this get() call ever happened. The remove()and set() methods would
just remove the map's reference to the value object, and would never change an
already returned object. Easy. But that’s not our case, we are working with
off-heap memory and have to manage it on our own.
Fundamentally, there are two ways to solve it:
- Change the
get()contract so it doesn't return a pointer. Instead, it receives a pointer from the outside and copies the value there. get()still returns a pointer, but the map guarantees the memory behind it stays immutable until the caller notifies the map that it’s done and that it won’t use the pointer anymore.
Option 1: Callers own the destination memory
The first option looks interesting. The new contract could look like this:
interface ConcurrentString2KeyMap {
void set(String username, long srcKeyPtr);
void get(String username, long dstKeyPtr);
void remove(String username);
}
The caller would own the dstKeyPtr pointer and the map would copy the key from
its internals to this pointer and forget this get() call ever happened.
This sounds quite nice at first, until we realize it just kicks the can down the
road: it forces every calling thread to maintain its own buffer to pass to
get(). If callers are all single-threaded, it’s still easy: each calling
object owns a buffer to pass to get() .
But if calling functions are themselves concurrent, it becomes more complicated. We have to make sure each calling thread uses a different buffer.
Ideally, the buffer would be allocated on stack, but this is Java so that’s not possible. We certainly do not want to allocate/deallocate a new buffer in the process heap for every invocation.
So what’s left? Pooling? That’s messy.
ThreadLocal? Even more messy and harder to put a cap on the number of buffers.
Maybe option 1 is not interesting as it seemed at first.
Option 2: Lifecycle notifications
Let’s explore the 2nd option. The contract remains the same as outlined in the
original proposal: long get(String username). We have to make sure the memory
behind the pointer remains unchanged until we are done.
The absolute simplest thing would be to use a read-write lock.
Each map would have a read-write lock associated, and then readers acquire a
read lock before calling get() and release it only after returning from
AuthCrypto.verifySignature():
boolean verifySignature(CharSequence username, long challengePtr, int
challengeLen, long signaturePtr, int signatureLen) {
map.acquireReadLock();
try {
long keyPtr = map.get(username);
return AuthCrypto.verifySignature(keyPtr, PUBLIC_KEY_SIZE_BYTES, challengePtr, challengeLen, signaturePtr, signatureLen);
} finally {
map.releaseReadLock();
}
}
Mutators would only have to acquire a write lock before calling set() or
remove(). Not only is this design simple to reason about, it is also simple to
implement.
Assuming that only set() and remove() change the internal state, we can just
take a single-threaded map implementation and it will do it. But there's a
catch... It violates our original requirements!
Readers are often on the hot-path and we want them to remain lock-free. The proposed design blocks readers when the map is being updated, so this is a no-go.
What can we do? We could change the locking schema to be more fine-grained - instead of locking the whole map we could lock particular entries. While this would improve practical behaviour, it would also complicate the map design and the readers could still be blocked when the same key is being updated.
What else? We could use an optimistic locking schema, but this brings its own intricacies.
It’s becoming clear that pointer lifecycle management will have to work in concert with the internal map implementation. So was this exercise completely fruitless? Not completely.
There is still one design idea we could reuse: Map users must explicitly notify that they are no longer using the pointer.
Let’s explore how to design map internals!
Designing a map for lock-free readers
I consider myself an experienced generalist. I know bits and bobs about concurrent programming, distributed systems and all kinds of other areas, but I’m not really narrowly specialized in any particular topic.
A jack of all trades and master of none? Probably. So when I was thinking about a suitable data structure, I did what every generalist would do in 2023: asked ChatGPT!
I was amazed GPT realized that I meant to write “single writer” and not “single reader”, which I took as proof that GPT knows what is it talking about! 🙂 So I read further: I might have heard about RCU before, but I have never used it myself. I found the description a bit too vague to be used as an implementation guide, and it was a lunch time anyway.
Copy-On-Write intermezzo
While walking to a lunch place, I was thinking about it more and got an idea. Why not use the Copy-On-Write technique to implement a persistent map?
That way, I could take a regular single-threaded map, and mutators would clone the current map, do their thing, and then atomically set this newly created map as the map for readers. Readers would then use whatever map was published as the latest. Published maps are immutable, thus always safe for concurrent readers, even from multiple threads, lock-free. In fact, even wait-free. Yay!
Additionally, we would have to introduce a mechanism for safe deallocation of map internal buffers when a stale (=no longer the latest published map) map has no readers. Otherwise, we would be leaking memory. That’s a complication, but it feels like something easily fixable with enough dedication and atomic reference counters.
So this all sounds good, but as have come to expect... there is still a catch. We need to allocate a block of memory for the map contents on every single mutation. We said that mutations are rare, so perhaps that’s not a big deal? Maybe it’s not, but one of the QuestDB design principles is to be conservative with memory allocations as they cost CPU cycles, memory bandwidth, cause CPU cache thrashing, and in general tend to introduce unpredictable behaviour.
Back to the drawing board: Map recycling
So I couldn’t implement a straightforward Copy-On-Write map, but I felt I was on the right path towards the goal: lock-Free readers. At some point I realized that, instead of allocating a new map whenever there is a change, I could keep reusing only 2 maps: one would be available for readers and the other for writers.
Once a map is published for readers, it’s guaranteed to be immutable as long as there is at least one reader still accessing it.
It would look similar to this:
class ConcurrentMap {
private InternalMap readerMap = new ...
private InternalMap writerMap = new ...
void set(String username, long keyPtr) {
getMapForWriters().set(username, keyPtr);
swapMaps();
}
long get(String username) {
return getMapForReaders().get(username);
}
void remove(String username) {
getMapForWriters().remove(username);
swapMaps();
}
}
The idea looks neat, but it’s clear the code as outlined above has a number of issues and open questions:
- The code always mutates just a single map, but we clearly need to keep both maps in sync. We cannot lose updates.
- Multiple mutating threads could step on each others toes.
- If
swapMap()unconditionally swaps reader and writer maps, the mutating thread performing two consecutive mutations could write into a map which still has some readers. This violates our invariant: we must not have readers and writers concurrently accessing the same internal map. - How to implement
getMapForWriters()andgetMapForReaders()? 🙂
Single-writer FTW!
Let’s start with problem #2 - multiple mutating threads.
We said that mutations are rare and never on the hot path. Hence, we can afford to be brutal and use a simple mutex - to make sure there is always at most a single mutator. The single-writer principle is known to simplify design of concurrent algorithms anyway.
Thus the map now looks like this:
class ConcurrentMap {
private InternalMap readerMap = new ...
private InternalMap writerMap = new ...
private final Object writeMutex = new Object();
void set(String username, long keyPtr) {
synchronized(writeMutex) {
getMapForWriters().set(username, keyPtr);
swapMaps();
}
}
long get(String username) {
return getMapForReaders().get(username);
}
void remove(String username) {
synchronized(writeMutex) {
getMapForWriters().remove(username);
swapMaps();
}
}
}
That was easy. Maybe violent, but easy.
Racing threads
Let’s explore something more complicated - problem #3 - multiple consecutive write operations. What do I mean by this?
Consider this scenario:
- We have 2 instances of
InternalMap, let’s call themm0andm1. - The field
readerMapreferences the mapm0andwriterMapreferencesm1. - Reader thread calls
map.get(). ThusgetMapForReaders()returnsm0. At this point the reader thread is paused by the OS. - Writer thread calls
map.set(). ThusgetMapForWriters()returnsm1. - Writer modifies
m1and swaps the maps. - The field
readerMapnow references the mapm1andwriterMapreferencesm0. - Another writer calls
map.set(). ThusgetMapForWriters()returnsm0and the writer starts mutating it. The write operation takes a while. - The OS resumes the reader thread from #3, and it starts reading
m0(because that’s the map the reader got before its thread was paused!) - At this point we have a reader thread concurrently accessing the same internal map instance as a writer thread -> Boom 💥💥💥!
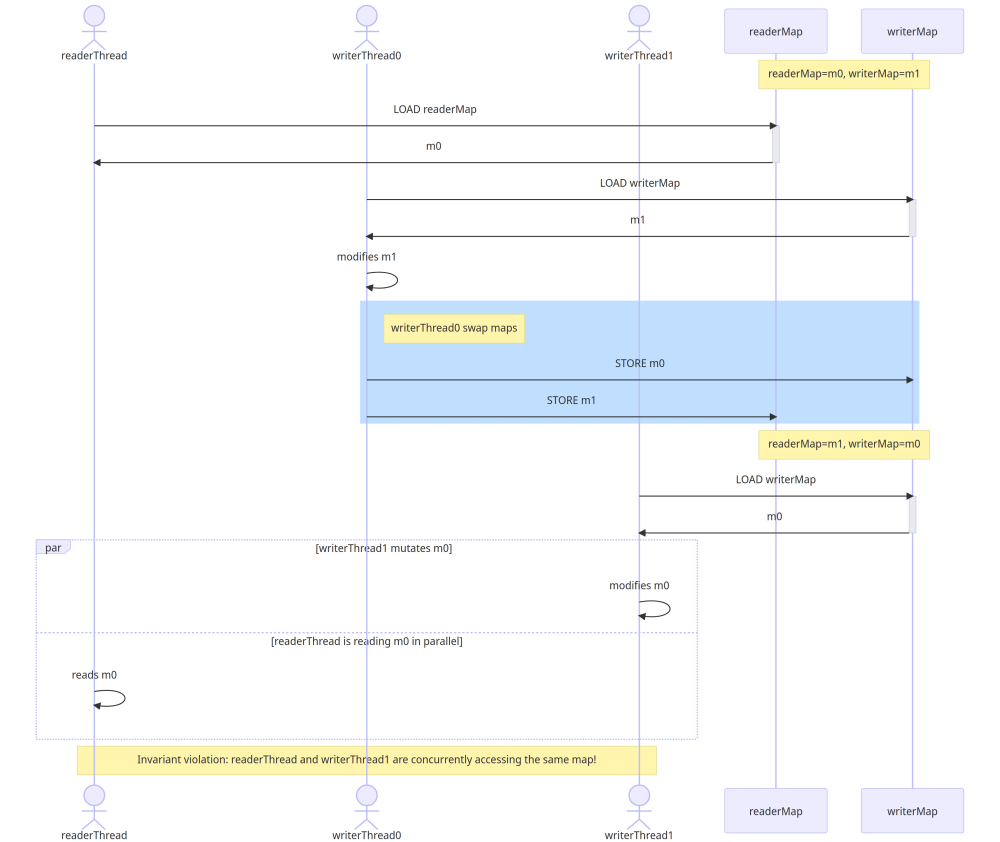
If the scenario looks too long and boring and you skipped it, here is a short
summary: a reader obtains mapForReaders and in the next moment this map
becomes writerMap. So what was once a readerMap is now a writerMap and
thus the next write operation can mutate it at will. Except the stale reader
still thinks the same map is safe for reading. That’s a bad concurrency bug!
How can we prevent the racy scenario outlined above? We already use a mutex on the write path, that’s almost as nasty as it gets. Almost?! Can we be even nastier? Sure we can!
Each internal map could have a reader counter and getMapForWriters() won’t
return until the reader counter on the current mapForWriters reaches 0. In
other words: the writer won’t mutate writerMap until all readers indicate they
are no longer using this map.
How about newly arriving readers? New readers don’t touch writerMap at all,
they always load the current readerMap so that’s not a problem.
Enough talking! Let’s see some code:
class ConcurrentMap {
private InternalMap readerMap = new InternalMap();
private InternalMap writerMap = new InternalMap();
private final Object writeMutex = new Object();
void set(String username, long keyPtr) {
synchronized(writeMutex) {
getMapForWriters().set(username, keyPtr);
swapMaps();
}
}
Reader concurrentReader() {
InternalMap map;
for (;;) {
map = readerMap;
map.readerArrived();
if (map == readerMap) {
return map;
}
map.readerGone();
}
}
private InternalMap getMapForWriters() {
InternalMap map = writerMap;
while(map.hasReaders()) {
backoff();
}
return map;
}
void remove(String username) {
synchronized(writeMutex) {
getMapForWriters().remove(username);
swapMaps();
}
}
interface Reader {
long get(String username);
void readerGone();
}
static class InternalMap implement Reader {
private final AtomicInteger readerCounter;
public void readerGone() {
readerCounter.decrement();
}
public void readerArrived() {
readerCounter.increment();
}
public boolean hasReaders() {
return readerCounter.get() > 0;
}
// the rest of a single threaded map impl
}
}
The code above looks way more complex than the previous buggy version.
Let’s go briefly through the changes:
- The most visible change: the
get()method is gone! Instead, there is a new methodconcurrentReader()which returns an interfaceReaderwith two methods:get()andreaderGone() - There is a skeleton of
InternalMap. It does not show any map-related logic, because it could be any single-threaded implementation of a map-like structure. It only demonstrates that each internal map has its own reader counter. - For the first time we see an implementation
getMapForWriters(). It’s really not doing anything else except waiting for all the stale readers from thewriterMapto disappear. Thebackoff()method may have various implementations and use primitives such asThread#yield()orLockSupport#parkNanos().
Counting readers
Let’s have a closer look at each change.
Why did we introduce the Reader interface? Isn’t it just an unnecessary
complication, and an example of the over-engineering so prevalent in Java
culture?
Well, maybe, but it simplifies the mechanism for readers to notify the map that they won’t access the returned pointer anymore.
How? Each internal map has its own reader counter. When a reader no longer needs
a pointer returned by a prior get(), it must invoke readerGone() on the
correct internal map.
The Reader interface does exactly that - it knows which instance of
InternalMap is in use. When a thread calls reader.readerGone(), it
decrements the reader counter on that map.
For example:
boolean verifySignature(CharSequence username, long challengePtr, int
challengeLen, long signaturePtr, int signatureLen) {
ConcurrentMap.Reader reader = map.concurrentReader();
try {
long keyPtr = map.get(username);
return AuthCrypto.verifySignature(keyPtr, [...]);
} finally {
reader.readerGone();
}
}
This hopefully made it clearer why we need the Reader interface.
A little aside: Do you still remember the design idea with a read-write-lock? I decided not to use it, because it could block readers. But the lock usage pattern was an inspiration for this notification mechanism.
Avoiding check-then-act bugs
Let’s focus on the implementation of concurrentReader() method.
It looks like this:
Reader concurrentReader() {
InternalMap map;
for (;;) {
map = readerMap;
map.readerArrived();
if (map == readerMap) {
return map;
}
map.readerGone();
}
}
It loads the current readerMap, increments its reader counter, and returns it
to the caller if - and only if - the readerMap field still points to the same
InternalMap instance. Otherwise, it decrements the reader counter to undo the
increment, and retries everything from start.
Why this complexity? Why do we need the retry mechanism at all? It’s to protect us against a similar problem with stale readers that we already discussed.
Consider this simpler implementation of concurrentReader():
Reader concurrentReader() { // buggy!
InternalMap map = readerMap;
map.readerArrived(); // increment the reader counter
return map;
}
// getMapForWriters() shown for reference only
private InternalMap getMapForWriters() {
InternalMap map = writerMap;
while (map.hasReaders()) {
backoff();
}
return map;
}
Broken down, we see that:
- There is a writer thread calling
map.set()and a reader thread callingmap.concurrentReader(). - The reader thread loads the current
readerMap, but the OS pauses it before it increments the reader counter. - The writer thread loads the current
writerMap, does a mutation, and swaps the maps. This means the oldreaderMapis now the newwriterMap. - At this point the reader has an instance of
InternalMapwhich is also set in thewriterMapfield. - There is another writer operation.
getMapForWriters()returns currentwriterMapimmediately, because the reader counter is still zero. The writer thread starts mutating the map. - The OS resumes the reader thread. The thread has a reference to the same internal map which is currently being mutated by the thread from the previous point.
- The reader thread increments the internal map reader counter, but that’s fruitless as the writer thread is already mutating the map.
- The reader thread
concurrentReader()returns a map which is being concurrently mutated by a writer thread -> Boom 💥💥💥!
The extra check in concurrentReader() is meant to prevent the above scenario.
It guarantees it incremented the reader counter on the map which is still the
current readerMap:
Reader concurrentReader() {
InternalMap map;
for (;;) {
map = readerMap;
map.readerArrived(); // increment the reader counter
if (map == readerMap) {
return map;
}
map.readerGone();
}
}
It is still possible that a reader thread increments the reader counter, returns
the Reader to the caller, and in the next microsecond a writer thread swaps
the maps so the map instance returned to the caller is now set as the
writerMap. This is entirely possible, but it won’t do any harm. The writer
won’t get access to the writerMap before its reader counter has reached zero.
What is left?
At this point we solved the hardest part of the concurrent algorithm, but there are still some unresolved issues:
- The map is still losing updates! We have 2 internal maps, but each update mutates just a single map.
- Some smaller bits:
- There is no happens-before relationship between writers swapping maps and readers loading them.
- The
close()method is not implemented so the map might leak native memory, etc.
Dealing with lost updates
We can fix the first problem. After swapping the maps, we could wait until the
current writerMap has no readers and then update it.
So mutation operations would look like this:
void set(String username, long keyPtr) {
synchronized(writeMutex) {
getMapForWriters().set(username, keyPtr);
swapMaps();
getMapForWriters().set(username, keyPtr);
}
}
This is a safe implementation as the getMapForWriters() guarantees that the
returned map has no readers and no new reader will arrive until the next swap.
On the other hand, it's inefficient: when we switch maps after writing, the new
writerMap may have stale readers, causing delays until they're cleared.
Is there a better option? It turns out that there is!
We could change the first map, swap them and remember the operation including
all parameters. During the next mutation we would replay the operation on the
mapForWriters and, if mutations are sufficiently rare, by the time we are
replaying the operation the writerMap has no longer any readers.
Let’s see the code:
void set(String username, long keyPtr) {
synchronized(writeMutex) {
InternalMap map = getMapForWriters();
replayLastOperationOn(map);
map.set(username, keyPtr);
swapMaps();
rememberSetOperation(username, keyPtr);
}
}
The map.remove() looks like this:
void remove(String username) {
synchronized(writeMutex) {
InternalMap map = getMapForWriters();
replayLastOperationOn(map);
map.remove(username);
swapMaps();
rememberRemoveOperation(username);
}
}
rememberSetOperation() must copy the memory under the pointer to its own
buffer, but we only have to remember a single operation. Given our blobs are
fixed-size, it allows us to keep reusing the same replay buffer. Zero
allocation.
Playing by the Java Memory Model rules
Now let’s do the last, important change.
This is how the ConcurrentMap looks like:
class ConcurrentMap {
private InternalMap readerMap = new InternalMap();
private InternalMap writerMap = new InternalMap();
private final Object writeMutex = new Object();
private final WriterOperation lastWriterOperation;
[...]
}
The whole mutable state is encapsulated in these 4 objects. The fields
writerMap and lastWriterOperations are only accessed by a writer thread
while holding a mutex. But the readerMap field is set by a writer thread and
then loaded by readers.
Readers are lock-free, they do not acquire any mutex before accessing the reader map. That is a data race and it could cause visibility issues.
The fix is easy, just mark the readerMap as volatile:
class ConcurrentMap {
private volatile InternalMap readerMap = new InternalMap();
private InternalMap writerMap = new InternalMap();
private final Object writeMutex = new Object();
private final WriterOperation lastWriterOperation;
[...]
The writer path now looks like this:
- Acquire a mutex
- Load the current
writerMap - Wait until all stale readers are gone
- Replay the last operation
- Do a new mutation
- Swap
readerMapandwriterMap - Remember the operation so it can be replayed on the untouched map during the new mutation
The readerMap is now marked as volatile, giving us
sequential consistency.
Colloquially speaking, the readers will see the most recent map swap done by a
writer thread. The readers are also guaranteed to see all changes which were
performed before the writer thread set the map as mapForReaders. And that’s
it!
Summary
We walked through a process of designing a concurrent data-structure which is lock-free on the read path. We could generalize some of the design principles we applied into the following rules:
- Single Writer Rule: Use a mutex for writes, ensuring only one writer at any time.
- Dual Maps: Maintain two maps – one for readers and another for the writer.
- Pointer Swap Mechanism: When a writer updates, it operates on the
mapForWritersand then switches the roles of the two maps. - Reader Counter: Each map has an atomic
readerCounter. As a reader begins, the counter increments and decrements upon completion. This ensures that no one accesses themapForWritersuntil all active readers from the previous swap have completed their reads. - Change Tracking: Writers, when updating
mapForWriters, log their modifications. This is crucial since we need to replicate these changes tomapForReaders, which might still be in use by some readers. Instead of waiting for all readers to shift to the new map, we log the change and apply it in the subsequent update. Given that we switch maps post-update, by the time of the next update,mapForWritersis likely free of old readers, allowing for immediate change application.
What’s next?
We have a working implementation of a concurrent map, but it’s not yet ready for production. There are still some issues to be solved:
- The
close()method is not implemented so the map might leak native memory. This is trivial to fix and I leave it as an exercise for the reader. - There are no tests! There are various ways to test concurrent data structures. You could use a stress test, where you spawn a lot of threads and let them mutate the map in a random way and then check the consistency of the map and some invariants. You could learn TLA+ and write a formal model of the map and then verify it.
- Performance optimizations. The current implementation uses the same write
path on both internal maps. Chances are that's not the best option. For
example there is no reason to calculate the hash code twice. There is no
reason to locate the bucket twice. The first
set()could remember which bucket was used and the secondset()could reuse it. We could also add batching to the writer path: the current implementation swaps the maps after every mutation. This is inefficient when writers are mutating the map in a tight loop.
Acknowledgements
After I finished the implementation, I got really excited and I wanted to share it with the world. I naively thought that I was the first one to come up with this idea. I was wrong.
First, I found the Double Instance Locking pattern at the amazing Concurrency Freaks blog. This pattern is very similar to the one I described here. It also uses 2 internals structures and readers are alternating between them. It uses a read-write lock to protect the map being mutated. Given there is only a single writer then at any given time there is at least one internal map which is available for reading. This gives readers lock freedom.
It's fair to say that the Double Instance Locking pattern is simpler to reason about. It decomposes the problem better. But I'd still argue my contribution is the trick with delayed replay of the last operation - if writers are sufficiently rare, then writers won't be blocked at all.
The same blog also links to the paper Left-Right: A Concurrency Control Technique with Wait-Free Population Oblivious Reads which on the surface also looks similar. It claims not only Lock-Freedom, but also Wait-Freedom. I have yet to deep dive into it.
I would like to thank to reviewers of this article: Andrei Pechkurov and Marko Topolnik. Thank you so much! Without your encouragement I would not find the courage to publish this article! ❤️ Of course, all the mistakes still left are solely my responsibility.